
A comparison of machine learning deployment methods on mobile devices and on servers.
Table of Contents
In my previous post, I talked about how I wanted to build a mobile app that works like Google Lens, but with my own image classification models. While there are plenty of online resources with example code on building a simple image classification model, there are not nearly enough on deployment. Nonetheless, I find a plethora of choices on where and how to deploy the model both fascinating and overwhelming.
While some people would say I’m digressing from ML, I would argue that deployment is an integral part of ML and it shouldn’t be dismissed. It is not my goal to become an expert in deploying ML applications, but I think knowing the basics and being aware of the different types of deployment options is essential as it will help me see the big picture and how different parts fit in. Even if I don’t ever need to do ML deployment in the future, this will still help me in designing better ML applications.
If data cleaning is the most unenjoyable part of machine learning for data scientists, then deploying the model is probably a close second. In fact, the skill set required by deployment is so different that it is usually done by a separate team.
In this post, I will give an overview of the choices available and discuss their trade-offs. I hope this will help you with your next ML application deployment.
Why Does Deployment Matters?
With the help of fastai, we can reduce the training of an image classification model to 3 lines of code:
data = ImageDataBunch.from_folder(path) # Load some images
learn = cnn_learner(data, models.resnet18, metrics=accuracy) # Load a model
learn.fit(1) # Train the model
After that, it’s just another line of code to make a prediction using the trained model:
prediction = learn.predict(img)
The crux of machine learning is basically trying to figure out how to improve prediction accuracy.
Armed with the above code, you can now call yourself a data scientist or whatever title tickles your fancy.
Jokes aside, it is amazing at how simple ML has become. Of course, this is just one example and there are many more problems where the solution isn’t nearly as simple if it is even solved. But you get my point.
The image classification model implementation in this first fastai project is similar to the above and also very simple. Most of the time will be spent on cleaning the data, which will have a high impact on prediction accuracy. Then the rest of the time is spent on deployment.
One of the most common ways of doing model training and ad-hoc prediction is on a Jupyter Notebook. But this method doesn’t work for a Google Lens type of app. You don’t want to take a picture with your phone, manually upload it to your computer, then make the prediction and see what the predicted outcome is. You would have to either carry your laptop or wait till you’re back home. This alone will probably throw you off the idea of building the app in the first place.
Instead, you would need to build a mobile app that can make and display predictions right away.
With that said, let’s explore the different ways I can deploy my mobile app.
Where Should Inference Take Place?
Inferencing is using a trained model to make predictions. Unlike training a model, it requires much less computing power. So little that even a smartphone nowadays can do it. A big part of deployment is to decide where and how inference takes place.
Inference for a mobile app can take place either at the mobile device or at the server. There are pros and cons to either approach and the following table summarizes some of the key differences:
| Mobile Device | Server | |
|---|---|---|
| Internet | Not required | Required |
| Internet Bandwidth | None | Depends on application |
| Internet Latency | None | High |
| Computing Power | Low | High |
| Privacy | Data stays on-device | Data leaks to server |
| Frameworks & Libraries | Restricted | No restrictions |
| Model Implementation Complexity | Approach depends on the framework and device OS (Android, iOS, etc) | None |
The decision to which approach to take will largely depend on your use case. For a simple image classification app, many of the factors regarding internet, computing power and privacy are much of a non-issue.
Instead, your decision will more probably be based on which framework you would like to use. Let’s explore what is available on the mobile device front.
Mobile Device Implementation
Here is a summary of the more common framework or approaches that you can use:
| Framework / Approach | Notes |
|---|---|
| TensorFlow Lite | - for building mobile native apps |
| TensorFlow.js | - for building web apps, which work on mobile and desktop |
| PyTorch -> ONNX -> Caffe2 | - PyTorch and Caffe2 might produce different model outputs due to slightly different implementations |
| PyTorch -> ONNX -> TensorFlow | - importing ONNX models into TensorFlow is still experimental |
| Google ML Kit | - API that provides inference access to on-device (via TensorFlow Lite) or cloud (via Google Cloud Vision API) - support custom TensorFlow Lite models which can be hosted on cloud (Firebase) or device - auto-updates of on-device models from cloud - auto-switching of using models from on-device or from cloud, depending on device connectivity - beta release |
| Core ML 2 | - iOS only |
Some interesting observations we see from the above:
- There are a plethora of choices for TensorFlow users as it is a relatively matured framework.
- ONNX (Open Neural Network Exchange) is an open standard that is gaining momentum. It allows the trained models from one framework to be used by another framework. Thus you can freely choose the framework for building and training your model, knowing that it can be deployed to other supported framework for inferencing. Besides addressing the framework preferences of different people, it also helps resolve the problem of framework lock-ins.
- Google ML Kit seems like a very interesting option. The idea that it allows auto switching of models between on-device and the cloud, while also supporting auto-update of on-device models, is very useful. We will probably see wider adoption of this approach as it moves out of the beta phase.
For the current app, there are several preferences that we would like to keep:
- The motivation is to apply the fastai library, thus using PyTorch is a must. (rules out TensorFlow Lite, TensorFlow.js, Google ML Kit)
- To have full control of the whole deployment process without dealing with another framework, in addition to any model translation complications (rules out ONNX)
- It works on Android and iOS (rules out Core ML2)
It seems that none of the on-device implementations fully fits the bill. Let’s explore the server-side approaches next.
Server Implementation
Unlike mobile device implementation, there are a lot more choices to choose from on the server side. The choices that you make will depend on factors such as:
- your level of knowledge of provisioning and managing servers
- the amount of time you are prepared to spend on infrastructure
- the computing power you need for your project
- the flexibility of the infrastructure to take heavier loads later on
- the amount of budget that you have
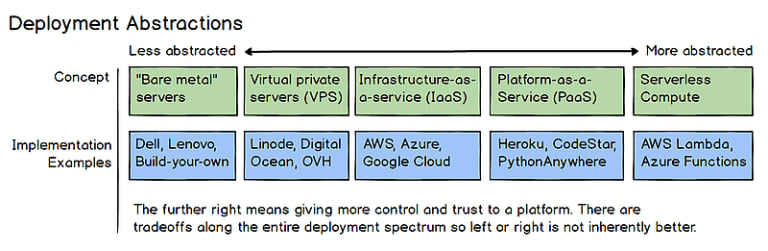
The spectrum of choices can be summarized on this chart (source)
Let’s pick a few of the above categories for a brief discussion.
IaaS - Infrastructure as a Service
This is for you if you are experienced in provisioning your own servers. You are required to set up the hardware configuration, and install the required software libraries for inference and communicating with the mobile device. Furthermore, the job of maintaining the server, libraries and scalability all falls on you. You will need to patch your server on a regular basis or risk having it hacked.
While the first step is to learn the functions of different cloud building blocks and how they fit in with each other, the next step of getting familiar with the pricing of all the services offered can get complicated quickly (or you may even dare to compare costs of different providers).
With great flexibility comes great power, and probably frustrations.
Pros:
- cost can be reduced to a minimal at all times through tweaking configurations while maintaining maximum performance
- valuable experience and skills that can be transferred to any projects or other providers
Cons:
- high degree of configuration can be overwhelming
- cost can be unexpectedly high if you are not familiar with how the pricing works, e.g. resources that you turned off are still being charged because they have not been decommissioned, or your app experienced an unexpectedly high amount of traffic and you haven’t put in place any alerts or countermeasures
- a large investment of time for anyone new in order to learn the “art of provisioning servers”, which might not be worth its weight if it doesn’t suit your goal
Providers:
VPS - Virtual Private Servers
VPS simplifies the process of hardware selection by giving you preselected configurations to choose from, thus vastly limiting the choices that you have to make. It’s like renting a preassembled computer a month at a time where your choices are “small”, “medium”, or “large”. You are charged a fixed fee per month and there isn’t much room (i.e. risk) to go over the fixed fee.
Pros:
- great choice for people new to the cloud
- much simpler to set up than IaaS
- many providers to choose from
- risk of “surprise charges” significantly reduced
Con:
- need to upgrade to a higher pricing tier even if only one of the resources needs to be upgraded e.g. you will need to pay for a higher tier if you need more memory but the other resources in the current tier are still under-utilized (processor, disk space, etc.)
- most people find the lack of customization becoming more of a problem as their application grows and their cloud knowledge increase
- more expensive than IaaS
Providers:
PaaS - Platform as a Service
PaaS offers a level of abstraction where you don’t need to “speak servers”. They usually come with a preinstalled OS, database, web server and a programming environment of a language of your choice. The cloud provider will handle any necessary server or software maintenance for you.
Another major advantage of PaaS over IaaS and VPS is it will auto-scale the server for you. You can define budgets beforehand and let the cloud provider handle the rest. This can be handy if your app hits the coveted Hacker News FP.
Pros:
- auto-scaling of services
- easier to manage than IaaS
- cheaper than MLaaS
- support Continuous Integration & Continuous Deployment through popular source code repositories (e.g. Github)
Cons:
- more setup required than MLaaS
- more expensive (usually) than IaaS
Providers:
ML PaaS - Machine Learning Platform as a Service
This is the newest offerings from cloud providers that give ML practitioners cloud computing power with as little infrastructure setup as possible. It can be considered as an ML flavoured form of PaaS. Each provider will have their own list of supported ML frameworks.
Pros:
- all the pros of PaaS
- good integration of all the infrastructure resources needed within the cloud provider to run a complete ML setup
- ability to choose the type of infrastructure (from a single computer to a computer cluster)
- GUI for building the whole ML project pipeline
- support hyperparameter tuning
- track experiment results
Cons:
- prone to lock-ins to a cloud provider (“Sticky Clouds”)
- most expensive
- might not have support for your particular ML framework
- hard to fine tune infrastructure for better performance and cost
Providers:
- Amazon SageMaker
- Google Cloud Machine Learning Engine (doesn’t currently support PyTorch)
- Microsoft Azure Machine Learning Service
Prebuild Models
This is a sub-type of ML PaaS (or maybe it’s a SaaS, Software as a Solution, who knows) that allows you to use their pre-trained models. These solutions reduce the whole image classification solution to a few API calls or a few clicks. You just upload your photos and it’ll give you information about the image which might already contain the information that you’re trying to predict. This is only useful if their pre-trained solutions overlap with the solution that you’re looking for, as you will not be able to do much customization. This is designed for people who don’t have any ML experience. Since we want to use our own trained model, we will not be considering this for our project.
Providers:
For our app, using the most basic option from any of the above solution would be sufficient. It’ll probably take is no more than 15 mins top. But what fun is that? (I’ve spent more time than I wish in the past provisioning servers) What if we don’t have to provision any servers?
Let’s look into this a bit more in the next post.